
在回答现在有什么面向AI的存储解决方案时,我们需要先了解一下,人工智能下的数据到底有哪些特征,基于这些数据,到底需要一个什么样的存储?
我们通过逐层分析,将最终过滤出AI业务对存储的综合诉求。
海量非结构化数据存储
AI业务中除了个别业务场景主要针对结构化数据进行分析外(例如消费记录、交易记录等风险控制、趋势预测场景),大多数场景需要处理的是非结构化数据,例如图像识别、语音识别、自动驾驶等,这些场景通常使用的是深度学习的算法,必须依赖海量图片、语音、视频的输入。
数据共享访问
多个AI计算节点需要共享访问数据。由于AI架构需要使用到大规模的计算集群(GPU服务器),集群中的服务器访问的数据来自一个统一的数据源,即一个共享的存储空间。这种共享访问的数据有诸多好处,它可以保证不同服务器上访问数据的一致性,减少不同服务器上分别保留数据带来的数据冗余等。
那么哪种接口能提供共享访问?
块存储,需要依赖上层的应用(例如Oracle RAC)实现协同、锁、会话的切换等机制,才能实现在多节点间共享块存储设备,因此不适合直接用于AI应用。
能实现共享访问的通常有对象存储和文件存储,从数据访问的接口层面看,好像都能实现数据共享。
但哪个接口更方便,我们需要深入地看一下AI的上层应用框架如何使用存储。我们以AI生态中非常流行的PyTorch为例,PyTorch在加载图片数据时,通常会调用以下程序:
|
1 2 3 |
from torchvision import datasets, transforms dataset = datasets.ImageFolder(‘path/to/data’, transform=transforms) |
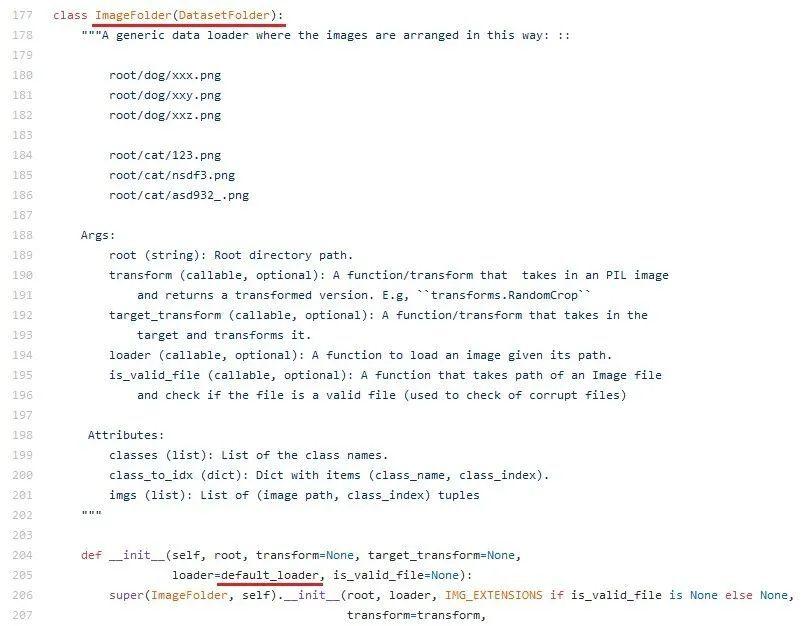
那么torchvision的datasets.ImageFolder如何加载图片呢?我们来看看ImageFolder的构造函数,这里面会有一个默认的default_loader:
除教程外,本网站大部分文章来自互联网,如果有内容冒犯到你,请联系我们删除!