链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
单链表有一个头节点head,指向链表在内存的首地址。链表中的每一个节点的数据类型为结构体类型,节点有两个成员:数据成员(实际需要保存的数据)和指向下一个结构体类型节点的指针即下一个节点的地址(事实上,此单链表是用于存放整型数据的动态数组)。
链表按此结构对各节点的访问需从链表的头找起,后续节点的地址由当前节点给出。
无论在表中访问那一个节点,都需要从链表的头开始,顺序向后查找。链表的尾节点由于无后续节点,其指针域为空,写作为NULL。如图:
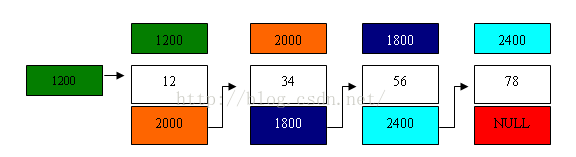
上图还给出这样一层含义,链表中的各节点在内存的存储地址不是连续的,其各节点的地址是在需要时向系统申请分配的,系统根据内存的当前情况,既可以连续分配地址,也可以跳跃式分配地址。 第 0 个结点称为头结点,它存放有第一个结点的首地址,它没有数据,只是一个指针变量。
以下的每个结点都分为两个域,一个是数据域,存放各种实际的数据,如学号 num,姓名 name,性别 sex 和成绩 score 等。另一个域为指针域,存放下一结点的首地址。链表中的每一个结点都是同一种结构类型。
我们把这些利用结构指针连接起来的结构变量称为链表(Link List),每一个结构变量(相当于链条中的每个环节)称为链表的结点(Node)
和数组一样,链表也可以用来存储一系列的数据,它也是电脑中存储数据的最基本的结构之一。
例如,一个存放学生学号和成绩的结点应为以下结构:
|
1 2 3 4 5 6 |
struct stu { int num; int score; struct stu *next; } |
前两个成员项组成数据域,后一个成员项 next 构成指针域,它是一个指向 stu 类型结构的指针变量。
链表的基本操作对链表的主要操作有以下几种:
1. 建立链表;
2. 结构的查找与输出;
3. 插入一个结点;
4. 删除一个结点
下面通过例题来说明这些操作。
例1. – 简单的链表
// A simple C program for traversal of a linked list
#include <stdio.h>
#include <stdlib.h>
struct Node {
int data;
struct Node* next;
};
// This function prints contents of linked list starting from
// the given node
void printList(struct Node* n)
{
while (n != NULL) {
printf(" %d ", n->data);
n = n->next;
}
}
int main()
{
struct Node* head = NULL;
struct Node* second = NULL;
struct Node* third = NULL;
// allocate 3 nodes in the heap
head = (struct Node*)malloc(sizeof(struct Node));
second = (struct Node*)malloc(sizeof(struct Node));
third = (struct Node*)malloc(sizeof(struct Node));
head->data = 1; // assign data in first node
head->next = second; // Link first node with second
second->data = 2; // assign data to second node
second->next = third;
third->data = 3; // assign data to third node
third->next = NULL;
printList(head);
return 0;
}