一)概论
文件系统描述了我们的数据。有了文件系统,我们才有文件夹、访问控制和命名文件。没有它们,我们的磁盘就只是一堆比特的混合物。我们不会知道任何东西存储的位置、起始或结束的地方,也不会有任何外部信息(元数据)。
文件系统的首要任务是保护我们的数据安全。我们希望数据能够快速访问,易于管理,最重要的是,它必须是正确的,并且位于我们放置的位置。存储硬件故障(硬盘崩溃)在统计上非常常见。这意味着,如果我们的数据对我们很重要,我们就需要更深入地研究存储管理。
很容易忽略文件系统而直接使用默认设置。在当今的 Linux 中,这通常意味着使用 ext4 或 XFS 文件系统。但我们还有其他更高级的选项:btrfs 和 ZFS。这些“下一代”文件系统让我们可以更灵活、更安全地处理大量存储。
在本文中,我们将探讨一些默认文件系统的功能,以及下一代文件系统所提供的优势。
二)默认文件系统:ext4 和 XFS
随着时间的推移,这两个文件系统已经逐渐满足了非常相似的需求。它们都是快速且可靠的日志文件系统。自 2009 年的 Karmic Koala 版本以来,Ubuntu 就默认使用 ext4 文件系统。2010 年的 Red Hat Enterprise Linux 6.0 也采用了 ext4。RHEL 7.0 于 2014 年转向使用 XFS。
文件系统是我们稳定系统的一个基本组成部分,因此内核和发行版维护人员在采用变更时会非常谨慎且缓慢。
如果我们今天安装 Ubuntu 或 Debian,存储将使用 ext4 文件系统。如果我们安装 Red Hat Enterprise Linux 或 SuSE,则会使用 XFS 文件系统。
2.1 昨天的高科技:日志、扩展和有限的校验和
自从引入到 Linux 以来,这两个文件系统在功能上越来越趋于相似。XFS 起初更为先进,并且仍然表现良好。然而,ext4 现在成功地添加了许多曾经使 XFS 与众不同的功能:
- 日志:文件系统的“日志”会记录所有对文件系统的更改副本。如果写入文件系统的操作被中断(例如断电),系统会检查日志并“重放”它,以尽量减少数据丢失和文件损坏。(此前,文件系统的正确性依赖于像 fsck 这样的“检查”工具。)
- 扩展:传统上,文件系统会逐块维护其内容的“映射”。默认块通常是 4,096 字节,随着存储量的增加,我们可以想象这些映射会变得多么庞大。相反,XFS 和 ext4 以较大的块(称为“扩展”)映射出数据片段。具体来说,扩展映射是两个数字:起始块地址和扩展的长度(以块为单位)。这对于大型卷和大文件来说非常有效,消除了跟踪每个块的文件归属的需求。
- 校验和:我们如何知道数据没有损坏?一种方法是计算校验和——当较大的数据发生变化时,校验和这个较短的“魔术数字”也会发生变化。我们过去通过运行检查和修复程序(如难以发音的 fsck)来实现这一点。XFS 和 ext4 现在会对元数据和它们的日志文件计算校验和。这很有用,但远不如 btrfs 和 ZFS 的逐块校验和那么全面。
尽管 ext4 和 XFS 都在它们的领域表现出色,但它们都不适用于一些当今更复杂的存储挑战。
2.2 ext 文件系统
“扩展文件系统”仍然是 Linux 中最流行的文件系统。从 1992 年的 ext 开始,这个文件系统很快在 1993 年升级到 ext2,并在 2001 年通过添加日志功能发展为 ext3,最终在 2008 年通过 ext4 实现了未来的兼容性改进。
ext4 文件系统
ext4 文件系统延续了其前身的理念:快速且在出现问题时修复它。然而,ext3 和 ext4 添加了数据安全功能,如日志和有限的校验和。
ext4 还支持更大的卷和文件(最大容量从 ext3 的 16 TB 增加)。它采用了 extents,这对处理大型文件(如媒体文件和一些数据库)非常有帮助。
但 ext4 同样在处理大量小文件时表现出色。它取消了 ext3 之前对子目录的限制(ext3 的限制为 32,000 个,尽管已经很慷慨)。
ext 系列文件系统之所以能作为 Linux 的默认文件系统存在如此之久,是因为它经过了充分的测试,优先考虑速度和“足够好”的数据验证。
2.3 XFS: 90年代为“大型计算机”设计
Silicon Graphics, Inc.(SGI)于1993年为其IRIX Unix操作系统创建了XFS文件系统。SGI以推动计算机图形生产的极限而闻名,他们依靠自己定制的高端和高度并行的硬件来实现这一目标。
XFS 是一个高性能的 64 位日志文件系统,最初由硅图形公司(SGI)在 1993 年为其 IRIX 操作系统开发。它专为“大型铁块”(即大型服务器和高端硬件)设计,目的是处理海量数据和高吞吐量的需求。SGI曾处于计算机图形生产的前沿,利用定制的高端、高度并行的硬件设备推动了技术的极限。这要求文件系统能够处理大文件、多CPU访问,并确保可靠性和性能。
在 Linux 系统中,XFS 因其卓越的性能和可扩展性,被广泛用于需要管理大数据量的环境中,例如服务器和数据中心。它的设计使其非常适合处理大型文件和复杂的文件系统结构,同时保持较高的 I/O 性能。
XFS的主要特点:
- 64位架构:XFS设计为64位文件系统,远在64位计算成为主流之前。这使得它能够处理非常大的文件和存储卷。
- 日志文件系统:为了防止文件损坏并确保可靠性,XFS包含日志记录功能,在实际写入磁盘之前记录更改。
- 可扩展性:XFS允许多个CPU同时访问文件,而无需在访问期间锁定i-node,这对具有数百个CPU核心的高性能计算环境至关重要。
XFS的设计重点在于细粒度并发,非常适合SGI的高度并行硬件。这使得XFS在SGI的生态系统中表现出色,类似于macOS和iOS为苹果硬件进行了优化。
XFS在Linux中的应用:
- XFS被移植到Linux,并于2001年成为Linux内核的一部分。如今,几乎所有主要的Linux发行版都支持XFS。
- 应用场景:XFS在需要大容量存储、大文件和多线程I/O操作的环境中表现优异,使其成为处理媒体文件、大数据或其他高需求工作负载的理想选择。
然而,对于较小、负载较轻的系统来说,由于ext4设计更简单且经过时间考验的可靠性,ext4可能是更好的选择。因此,如果您的系统需要处理大量数据处理任务,XFS可能是理想之选。但如果您运行的是较轻的任务,如微服务,ext4可能更适合。
我们可以想象允许潜在的数百个 CPU 核心同时访问所带来的额外复杂性!但为他们的高度并行的硬件设计这样精细的软件系统是值得的。就像 macOS 和 iOS 适用于苹果硬件一样,XFS 适合 SGI 的生态系统。
如果我们正在构建一个具有大存储需求、大文件和多线程 I/O 的系统,我们应该考虑使用 XFS。但对于较小和较轻的负载,ext4 可能更适合我们。
我们的系统会处理大量媒体文件或大数据吗?如果是这样,我们应该考虑 XFS 或其他下一代文件系统。我们会运行微服务吗?如果是这种情况,我们可能想继续使用 ext4。
2.4 动手实践
体验不同文件系统的最简单方法是全新安装 Linux。但如果我们想在现有系统上进行实验,这也是一个可行的选择。
ext4 文件系统已经无处不在。让我们看看 /sbin 目录中的内容:

这些链接方便地运行了 mke2fs 二进制文件,当然我们也可以直接运行它,并使用 -t 选项指定文件系统类型。
首先,我们要仔细检查,确保不会意外覆盖我们想要保留的文件系统。可以使用 lsblk 查看可用的块设备,并通过 df 比较已挂载的设备。
接下来,只需将 mkfs 程序指向目标设备,就可以开始了:
|
1 |
sudo /sbin/mkfs.ex4 /dev/sdc |
然后,我们创建一个目录作为挂载点,并运行 mount 命令。如果我们希望每次重启系统时都能自动挂载新文件系统,需要在 fstab 文件中添加一行配置。
如果我们想使用 XFS 文件系统,可能需要先安装用户空间工具。(大多数内核已经内置了对 XFS 文件系统的支持,我们只需要安装那些让我们能够创建和操作 XFS 文件系统的程序。)
在 Debian 和 Ubuntu 上,我们可以使用 apt 命令安装 xfsprogs 软件包:
|
1 2 |
sudo apt update sudo apt install xfsprogs |
安装完成后,我们就可以创建和管理 XFS 文件系统了。
然后运行相应的命令,用 XFS 初始化我们的块设备:
|
1 |
sudo /sbin/mkfs.xfs /dev/sdc |
一旦挂载完成,我们就可以开始实验,看看它是否满足我们的需求了!
2.5 RAID 和逻辑卷管理器
RAID(独立磁盘冗余阵列)和逻辑卷管理器(LVM)是管理 Linux 系统中存储的关键工具。它们在使用多个磁盘时,可以提高性能、提供冗余并增加灵活性。
RAID:独立磁盘冗余阵列
RAID 是一种将多个物理磁盘驱动器组合成一个逻辑单元的技术。RAID 的主要目的是增加数据冗余(以防止磁盘故障)并提高性能。RAID 级别根据这两个目标的平衡而有所不同。
- RAID 0(条带化): 数据分布在多个磁盘上以提高性能,但没有冗余。如果一个磁盘发生故障,所有数据将丢失。
- RAID 1(镜像): 数据在两个磁盘上复制,提供冗余。如果一个磁盘发生故障,另一个磁盘上有完整的副本。
- RAID 5(带奇偶校验的条带化): 数据和奇偶校验信息分布在三个或更多磁盘上,提供冗余并提高性能。
- RAID 6(双重奇偶校验的条带化): 类似于 RAID 5,但有两组奇偶校验信息,可以应对两个磁盘同时发生故障。
- RAID 10(1+0): 结合 RAID 1 和 RAID 0,通过镜像和条带化数据,提供冗余和性能优势。
逻辑卷管理器(LVM)
与传统分区相比,LVM 提供了一种更灵活的磁盘存储管理方式。通过 LVM,您可以将多个物理磁盘聚合成一个逻辑卷,然后可以将其分割成多个用于不同用途的逻辑卷。
LVM 的关键概念:
- 物理卷(PV): 原始存储设备,如硬盘或 RAID 阵列。
- 卷组(VG): 物理卷的集合,可以看作是一个存储池。
- 逻辑卷(LV): LVM 中相当于磁盘分区的部分,逻辑卷是从卷组中划分出来的。
- 逻辑扩展(LE): 逻辑卷中的最小存储单位,类似于磁盘上的块。
LVM 的优势:
- 动态调整大小: LVM 允许您在不卸载卷的情况下调整卷的大小。
- 快照功能: 您可以对逻辑卷进行快照,这对于备份非常有用。
- 管理方便: 您可以轻松地向卷组添加或移除磁盘,根据需要调整存储空间,而不需要太多麻烦。
同时使用 RAID 和 LVM
RAID 和 LVM 可以结合使用,创建既有冗余又灵活的存储配置。例如,您可以创建一个 RAID 5 阵列来提供冗余和性能,然后在这个 RAID 阵列之上使用 LVM 来更灵活地管理存储。
RAID 和逻辑卷管理器的功能不同,但它们都允许我们将多个物理磁盘视为一个抽象的卷。
我们不是直接在块设备上创建文件系统,而是将磁盘添加到一个集合中,然后将该集合视为一个具有单一文件系统的设备。
例如,我们可能有两个磁盘(在 LVM2 的术语中称为物理卷)组合成一个虚拟卷。
|
1 2 3 4 5 6 7 8 9 10 11 |
lsblk -f -e7 -o NAME,FSTYPE,FSVER,FSAVAIL,MOUNTPOINT NAME FSTYPE FSVER FSAVAIL MOUNTPOINT sda ├─sda1 ext2 1.0 63.9M /boot ├─sda2 └─sda5 LVM2_member LVM2 001 ├─salvage--vg-root ext4 1.0 388.7G / ├─salvage--vg-swap_1 swap 1 [SWAP] └─salvage--vg-home ext4 1.0 274.2G /home sdb LVM2_member LVM2 001 └─salvage--vg-root ext4 1.0 388.7G / |
在这里,sda5 分区和 sdb 驱动器都是物理驱动器(可以使用 pvdisplay 检查),它们被收集到一个卷组中(可以使用 vgdisplay 检查),并分配到逻辑卷中,这些逻辑卷上存放着文件系统(可以使用 lvdisplay 检查)。
注意到根挂载点(salvage–vg-root)如何使用来自两个不同物理驱动器(sda5 和 sdb)的空间了吗?现代 Linux 多年来一直使用 LVM(逻辑卷管理),使我们能够使用所有可用空间,或者将一些空间预留为实时镜像副本。
我们还可以添加新的物理磁盘,并调整我们的卷和文件系统的大小。这种灵活性非常方便!
我们如何选择分布数据既有风险也有回报。如果一个磁盘损坏,我们会丢失数据吗?如果我们使用 10 个磁盘,而其中两个损坏了呢?
这些问题对于长期数据存储至关重要,但传统的 RAID 和 LVM 解决方案对此的回答方式非常不同。ZFS 和 btrfs 提供了更为集成的方法来应对这些问题,我们将在本文后面详细讨论。
三)下一代文件系统:是什么和为什么
传统的、经过时间考验的文件系统已经具备了许多出色的功能!那么,为什么我们还需要新的东西呢?
确实,对于某些用例来说,传统且值得信赖的解决方案已经非常合适了。
但新的文件系统能够解决并整合存储问题。ZFS 将 RAID 控制器、卷管理器和文件系统结合在一起,并且它还在重新思考文件系统的挂载和共享方式。而 btrfs 实现了几个类似的功能目标,同时避免了重新设计我们对存储的基本假设。
3.1. 新的热门特性:写时复制、错误检测、快照和复制
btrfs 和 ZFS 都强调了相较于之前文件系统的三种特别设计和功能改进。
写时复制(Copy-on-Write, COW) 的工作原理是不覆盖原数据,而是将数据写入磁盘的新区域。这种方法避免了文件或文件系统进入不一致状态的风险。在旧有的文件系统中,我们可能在保存文件时遇到问题(如断电、硬件故障、宇宙射线等),这可能导致文件损坏。
相反,COW 文件系统中,数据在内存中的更改被写入磁盘的新区域。完成后,所有指向该文件的引用都会更新为指向磁盘上的新位置。
例如,目录项保持其内所有文件及其块地址的列表。一旦新的副本完成(而不是之前),目录项才会被更改以指向新的块地址。元数据的更改也采用类似的过程。
COW 的另一个关键元素是,如果文件没有发生变化,则不需要进行复制。 相反,“浅拷贝”有点类似于符号链接,只有在实际发生变化时才会复制数据。
错误检测 现在由文件系统逐块完成。在过去,我们需要运行 fsck 来修复可能的数据错误。使用 ext4 或 XFS,我们仍然需要等待日志回放。旧式 RAID 需要较长时间来重建,因为它必须检查所有其他磁盘。
更糟的是:我们现在知道,随着驱动器变得更大,越来越多的静默数据损坏错误未被检测到。具有块级校验和可以让我们依赖文件系统来修复这些错误。
例如,ZFS 可能有一个文件分布在多个驱动器上,其各个块进行了镜像和重复。如果这些块中的一个变得损坏,其校验和会发生变化。
ZFS 计算该校验和和其镜像块的校验和,并将这些与最后一次更新该块时存储的校验和进行比较。如果文件是完整的,这些校验和应该都是相同的。如果其中一个校验和不对,我们知道该块已经损坏。然后,ZFS 可以自动使用具有已知良好校验和的块来“修复”损坏的块。
卷当前状态的快照 允许回滚和复制。我们理解 Copy-on-Write 意味着我们可以有轻量级的“浅”副本,它们只在数据被添加或更改时占用新的空间。这使得我们能够—类似于在进行风险更改之前对虚拟机进行快照—对计算机的状态进行快照。
我们还可以使用发送和接收命令来传输快照以及两个快照之间的差异。这些命令在 btrfs 和 ZFS 上都存在。(甚至有一些云复制服务!)
四)更好的/更全面的文件系统
btrfs,或称为“B-树”文件系统,尝试以更简单的方式(并且涉及较少的许可问题)将许多 ZFS 的进展引入 Linux。自 2009 年以来,它已经在 Linux 内核中存在,但仍在积极开发中。
4.1 btrfs 实操
体验 btrfs 的最简单方法之一是使用 Fedora 33 或更高版本进行全新安装。我们可以在不必深入了解其复杂功能的情况下,轻松上手 btrfs。以下是 Fedora 安装的步骤:
|
1 2 3 4 5 6 7 |
lsblk -f -o NAME,FSTYPE,LABEL,MOUNTPOINT NAME FSTYPE LABEL MOUNTPOINT sr0 zram0 [SWAP] vda ├─vda1 ext4 /boot └─vda2 btrfs fedora_localhost-live /home |
我们可以看到 ext4 仍然是 Fedora 选择的启动分区文件系统。
如果我们想在 Ubuntu 或 Debian 上尝试 btrfs,我们需要一些额外的工具。就像我们对 XFS 所做的那样,我们可以通过 apt 安装这些工具:
|
1 |
sudo apt install btrfs-progs |
从那里,我们可以使用 mkfs.btrfs 来创建新的 btrfs 卷,并使用 btrfs device add 来扩展卷:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
sudo mkfs.btrfs -L media -d raid1 /dev/vdb /dev/vdc btrfs-progs v5.13 See http://btrfs.wiki.kernel.org for more information. Label: media UUID: 0ec28d06-b5a1-46f3-b628-30d04aeaaef3 Node size: 16384 Sector size: 4096 Filesystem size: 20.00GiB Block group profiles: Data: RAID1 1.00GiB Metadata: RAID1 256.00MiB System: RAID1 8.00MiB SSD detected: no Zoned device: no Incompat features: extref, skinny-metadata Runtime features: Checksum: crc32c Number of devices: 2 Devices: ID SIZE PATH 1 10.00GiB /dev/vdb 2 10.00GiB /dev/vdc |
这个输出提供了很多细节和一些新的术语,比如“扇区大小”。虽然我们这里不详细讨论这些,但它们是有趣的起点。
与 ZFS 不同,我们需要挂载我们的新 btrfs 卷。一个简单的方法是使用 mount 命令或在 fstab 文件中通过卷的标签来引用它:
|
1 2 3 |
ls /dev/disk/by-label/ fedora_localhost-live media # mkdir /big-media; mount /dev/disk/by-label/media /big-media |
4.2 高级功能和风险
简而言之,btrfs 可以用作简单的文件系统,也可以作为 RAID 控制器和文件系统。然而,开发者警告不要在生产环境中使用 RAID5 配置,因为它可能存在不稳定的问题。
高级功能
- 快照(Snapshots)
btrfs 支持创建文件系统的快照,这允许我们捕获当前状态的完整副本。快照可以用于快速恢复系统状态,或用于备份和测试。这些快照是基于写时复制(COW)机制的,这意味着在创建快照后,只有更改的数据才会占用额外的空间。 - 增量备份(Incremental Backups)
利用快照,我们可以创建增量备份,即仅备份自上次备份以来发生变化的数据。这种方法减少了备份所需的存储空间和时间。 - 自我修复(Self-Healing)
类似于 ZFS,btrfs 也具有自我修复功能。它通过校验和机制检测和修复损坏的数据块。如果文件系统的某个部分出现错误,btrfs 会尝试从镜像数据中恢复这些错误的数据。 - 子卷(Subvolumes)
btrfs 允许创建逻辑上的子卷,这些子卷可以视为独立的文件系统。它们可以有不同的挂载选项,并且支持独立的快照和备份。 - 压缩(Compression)
btrfs 支持数据压缩,可以减少存储占用并提高磁盘利用率。常见的压缩算法包括 zlib 和 lzo。 - RAID 功能(RAID Functionality)
btrfs 内置了 RAID 功能,支持 RAID 0、RAID 1、RAID 10、RAID 5 和 RAID 6 配置。这些功能允许在同一文件系统中实现不同的冗余和性能特性。
风险
- 稳定性和成熟度
尽管 btrfs 提供了许多高级功能,但它在稳定性和成熟度方面可能不如 ZFS 或 ext4。特别是在生产环境中,某些功能可能尚未完全稳定或成熟。 - 数据恢复
在某些情况下,btrfs 的数据恢复功能可能不如其他文件系统(如 ZFS)强大。虽然它具备自我修复能力,但在处理复杂数据损坏时,恢复过程可能更具挑战性。 - 性能开销
使用高级功能(如压缩和校验和)可能会引入额外的性能开销。在某些情况下,这可能会影响系统的总体性能,特别是在资源有限的环境中。 - 复杂性
尽管 btrfs 的功能非常强大,但它也带来了相应的复杂性。配置和管理 btrfs 可能需要更高的学习曲线,特别是对于没有经验的用户。 - 开发和支持
btrfs 虽然在积极开发中,但相较于其他成熟的文件系统,可能缺乏长期支持和广泛的社区验证。这可能导致在遇到问题时,解决方案和支持的获取更加困难。
随着我们逐渐熟悉 btrfs,我们可以通过以下命令探索更多复杂的功能:
btrfs subvolume:将卷划分为子卷,并应用特定设置。btrfs subvolume snapshot:创建一个轻量的“影子”副本,用于备份或配置管理。btrfs balance:重新分配所有存储上的已使用块。btrfs send和btrfs receive:在机器之间传输快照。
btrfs 是一个不断发展的文件系统,任何对其使用的深入投资都必须伴随频繁查阅其 FAQ。
五)ZFS : 我们的全能存储解决方案
ZFS 起源于 OpenSolaris,首次发布于 2005 年。它很快被 Solaris 10 和开源的 BSD 操作系统采纳,并在 2014 年的 FreeBSD 10 中正式得到支持。
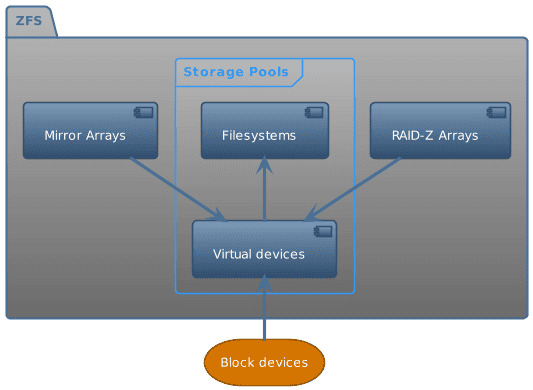
ZFS 允许我们像逻辑卷管理器一样对存储进行池化。它提供了类似于 RAID 的数据和硬件冗余(虽然它更像是一个智能的 JBOD)
ZFS 文件系统是一种结合了文件系统和逻辑卷管理器功能的现代存储解决方案。它最初在 OpenSolaris 中开发,并且在 2005 年发布。ZFS 的设计目的是提供高性能、高容量和高可靠性,并解决传统文件系统和存储管理中的许多问题。以下是 ZFS 的一些主要特点:
- 存储池(Storage Pools):ZFS 允许将多个物理磁盘组合成一个存储池(zpool),并在这个池上创建文件系统。这样,我们可以像处理单个卷一样管理整个存储池中的所有磁盘,提高了存储的灵活性和管理效率。
- 数据冗余和完整性:ZFS 提供内建的数据冗余,通过镜像(mirroring)和条带化(striping)来保护数据。它还使用校验和来检测和修复数据损坏,确保数据的完整性。
- 快照和复制:ZFS 支持高效的快照(snapshot)和复制(replication),允许我们创建文件系统的只读快照,并能够轻松地将数据从一个系统复制到另一个系统。这些特性对备份和灾难恢复非常有用。
- 自修复能力:当 ZFS 检测到数据损坏时,它可以自动使用冗余数据进行修复。通过比较数据块的校验和,ZFS 能够识别并纠正损坏的块。
- 压缩和去重:ZFS 支持内建的透明数据压缩和去重功能,可以节省存储空间,提高存储效率。
- 简化管理:ZFS 的设计旨在简化存储管理,减少传统文件系统中的复杂性,例如通过自动管理存储空间和避免手动干预。
5.1. ZFS 实操
由于许可问题,ZFS 在 Linux 上的历史较为复杂。目前在 Linux 上使用 ZFS 的最直接方法是通过使用 Ubuntu。我们可以安装 zfsutils-linux 软件包,或者 Canonical 在其安装镜像中默认包含了它。
这是一项“高级功能”,但我们可以将 ZFS 作为安装和启动的文件系统。这里,我们将其安装到一个虚拟测试系统上:
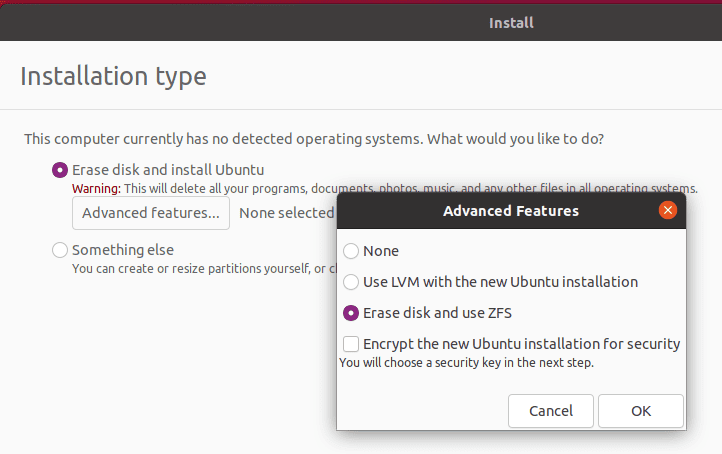
选择“使用 ZFS”后,其他一切都是透明的。真是把复杂性剔除,让我们直接使用有用的功能,Canonical 处理得真好!
5.2. ZFS 池
ZFS 通过创建池(pools)来管理存储,这种方法类似于逻辑卷管理器。池是由一个或多个磁盘组成的存储集合。与传统的文件系统不同,ZFS 通过池来抽象化存储设备,使得存储管理更加灵活和高效。
以下是 ZFS 池的一些基本概念:
- 池(Pool):ZFS 池是一个由多个物理磁盘组成的存储单元。它将这些磁盘整合成一个单一的虚拟存储设备。ZFS 池可以动态地扩展,添加更多的磁盘以增加存储容量。
- 文件系统(Filesystem):在 ZFS 池上创建的文件系统。每个池可以包含多个文件系统,它们可以有不同的设置和用途。
- 卷(Volume):ZFS 还支持卷,这是一种类似于块设备的虚拟磁盘,用于需要特定大小和性能的应用场景。
- 冗余:ZFS 池可以配置冗余设置,例如镜像(mirroring)或奇偶校验(RAID-Z),以提供数据保护和容错能力。
- 动态调整:ZFS 允许在运行时动态地调整池和文件系统的大小,无需停机或重启系统。
创建和管理 ZFS 池的过程相对简单。使用 zpool create 命令可以创建新的池,并使用 zpool status 查看池的状态。对于已创建的池,可以使用 zfs create 来创建新的文件系统。
在Ubuntu ZFS 安装后,我们看到这些块设备:
|
1 2 3 4 5 6 7 8 9 |
lsblk -e7 -f -o NAME,FSTYPE,LABEL,FSUSE%,MOUNTPOINT NAME FSTYPE LABEL FSUSE% MOUNTPOINT sr0 vda ├─vda1 ├─vda2 vfat 3% /boot/efi ├─vda3 swap [SWAP] ├─vda4 zfs_member bpool └─vda5 zfs_member rpool |
那么,什么是 bpool 和 rpool 呢?我们可以使用 zpool 命令来检查:
|
1 2 3 4 |
zpool list NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT bpool 1.12G 148M 1004M - - 0% 12% 1.00x ONLINE - rpool 22G 3.52G 18.5G - - 3% 16% 1.00x ONLINE - |
嗯,我们看到 bpool 是两个池中较小的一个。如果我们查找相关信息,会发现 Ubuntu 决定将安装分为“boot”(启动)和“root”(根)池。
如果我们将其与 LVM 示例中的分区方法进行比较,可以回忆起非 ZFS 的 Ubuntu 布局将 /boot 保留在一个专用的 ext2 分区上,而 /home 和 /(根目录)则在不同的逻辑卷中。
让我们看看 Ubuntu 是如何组织我们的 ZFS 池的:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
zfs list NAME USED AVAIL REFER MOUNTPOINT bpool 147M 876M 96K /boot bpool/BOOT 147M 876M 96K none bpool/BOOT/ubuntu_70wzaj 147M 876M 81.7M /boot rpool 3.52G 17.8G 96K / rpool/ROOT 3.51G 17.8G 96K none rpool/ROOT/ubuntu_70wzaj 3.51G 17.8G 2.44G / rpool/ROOT/ubuntu_70wzaj/srv 96K 17.8G 96K /srv rpool/ROOT/ubuntu_70wzaj/usr 336K 17.8G 96K /usr rpool/ROOT/ubuntu_70wzaj/usr/local 240K 17.8G 128K /usr/local rpool/ROOT/ubuntu_70wzaj/var 993M 17.8G 96K /var rpool/ROOT/ubuntu_70wzaj/var/games 96K 17.8G 96K /var/games rpool/ROOT/ubuntu_70wzaj/var/lib 983M 17.8G 862M /var/lib rpool/ROOT/ubuntu_70wzaj/var/lib/AccountsService 168K 17.8G 104K /var/lib/AccountsService rpool/ROOT/ubuntu_70wzaj/var/lib/NetworkManager 404K 17.8G 140K /var/lib/NetworkManager rpool/ROOT/ubuntu_70wzaj/var/lib/apt 79.5M 17.8G 79.2M /var/lib/apt rpool/ROOT/ubuntu_70wzaj/var/lib/dpkg 40.2M 17.8G 31.2M /var/lib/dpkg rpool/ROOT/ubuntu_70wzaj/var/log 8.41M 17.8G 3.19M /var/log rpool/ROOT/ubuntu_70wzaj/var/mail 96K 17.8G 96K /var/mail rpool/ROOT/ubuntu_70wzaj/var/snap 532K 17.8G 532K /var/snap rpool/ROOT/ubuntu_70wzaj/var/spool 280K 17.8G 112K /var/spool rpool/ROOT/ubuntu_70wzaj/var/www 96K 17.8G 96K /var/www rpool/USERDATA 4.99M 17.8G 96K / rpool/USERDATA/a_40qa3s 4.73M 17.8G 2.43M /home/a rpool/USERDATA/root_40qa3s 168K 17.8G 112K /root |
Canonical 在 rpool 中设置了许多子文件系统。这样一来,我们对存储池的各个部分就有了非常细致的控制。如果我们向 rpool 添加一个磁盘或磁盘集,就可以在任意位置或所有地方使用这些新空间。(向现有池中添加存储有一些复杂的元素,因此在购买之前需要先进行研究。)
我们在这里看到的每个挂载点都可以有自己的设置——配额、压缩和 IO 调整。而更棒的是:默认情况下,它们会继承父级的设置。如果我们使用 zfs 命令将 /var 设置为自动压缩:
|
1 |
sudo zfs set compression=lz4 rpool/ROOT/ubuntu_70wzaj/var |
现在,/var 目录下的所有内容都会使用 lz4 压缩。
在较小的系统上,这可能不会有太大影响,但如果我们需要扩展系统规模,ZFS 这种工作方式将会非常有用。
5.3. 创建我们自己的存储池
要开始,我们只需要一个简单的命令。
不过,在此之前,我们需要识别我们的磁盘。我们可以向虚拟机添加两个小型存储设备。Ubuntu 的 bpool 和 rpool 安装在 /dev/vda 上,所以这两个新添加的设备将分别是 /dev/vdb 和 /dev/vdc。
zpool 命令有许多选项。zpool create 命令可以将驱动器组装成 vdevs(虚拟设备),然后将这些 vdevs 组装成一个池:
|
1 |
zpool create mpool /dev/vdb /dev/vdc |
或者,它可以创建一个由这两个存储设备组成的单一镜像 vdev(虚拟设备):
|
1 |
zpool create mpool mirror /dev/vdb /dev/vdc |
该命令要求 ZFS 创建一个新的存储池。该存储池将被命名为 “mpool”,但我们可以选择任何名字。这个池将由一个镜像的 vdev(虚拟设备)组成,而该 vdev 由 vdb 和 vdc 设备组成。
创建好 mpool 之后,我们可以使用 zpool status 来检查其详细信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
zpool status mpool pool: mpool state: ONLINE config: NAME STATE READ WRITE CKSUM mpool ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 vdb ONLINE 0 0 0 vdc ONLINE 0 0 0 errors: No known data errors |
我们会注意到它已经自动挂载了:
|
1 2 3 |
df /mpool Filesystem 1K-blocks Used Available Use% Mounted on mpool 9650176 128 9650048 1% /mpool |