
🚀 Pipeline:让 CPU 快10倍的关键
你已经做出了一个 CPU。
但它还不够快。
问题不在计算能力,而在:
👉 执行方式
🔍 一、为什么你的 CPU 很慢?
在当前设计里(单周期 CPU):
👉 一次只能执行一条指令
执行流程是这样的:
|
1 2 |
Fetch → Decode → Execute → Memory → Write Back |
👉 每条指令必须走完全部流程
👉 下一条才能开始
👉 结果:
|
1 2 |
1条指令 = 5个阶段时间 |
👉 这就是瓶颈
⚡ 二、Pipeline 的核心思想
Pipeline(流水线)做了一件事:
让多条指令同时执行不同阶段
👉 类比:
洗衣服流程:
|
1 2 |
洗 → 烘 → 折 |
单周期:
|
1 2 |
洗完一件 → 再洗下一件 |
Pipeline:
|
1 2 3 4 |
第1件在烘 第2件在洗 第3件准备中 |
👉 结果:
👉 吞吐量大幅提升
🏗️ 三、5-stage Pipeline 结构(核心🔥)
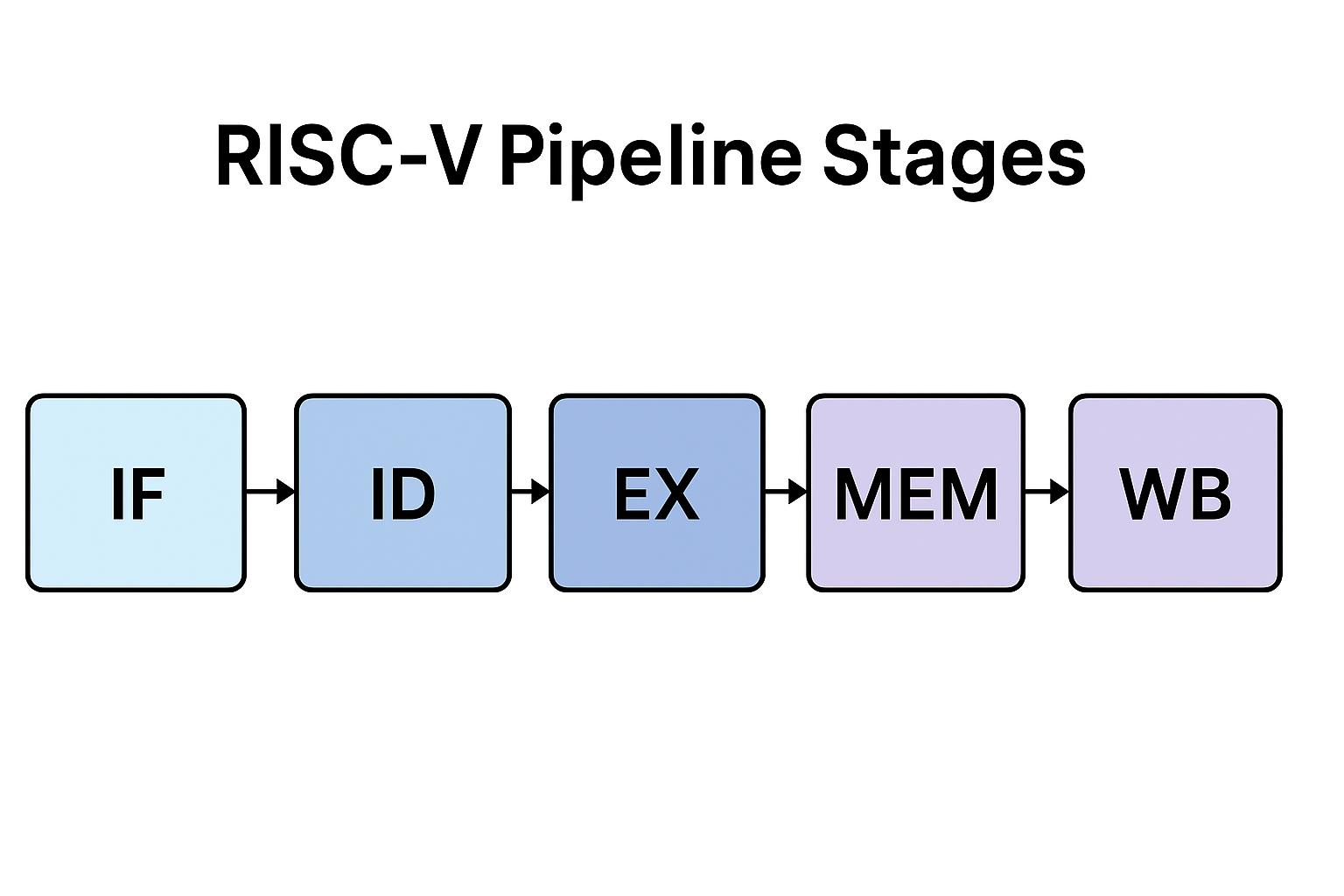
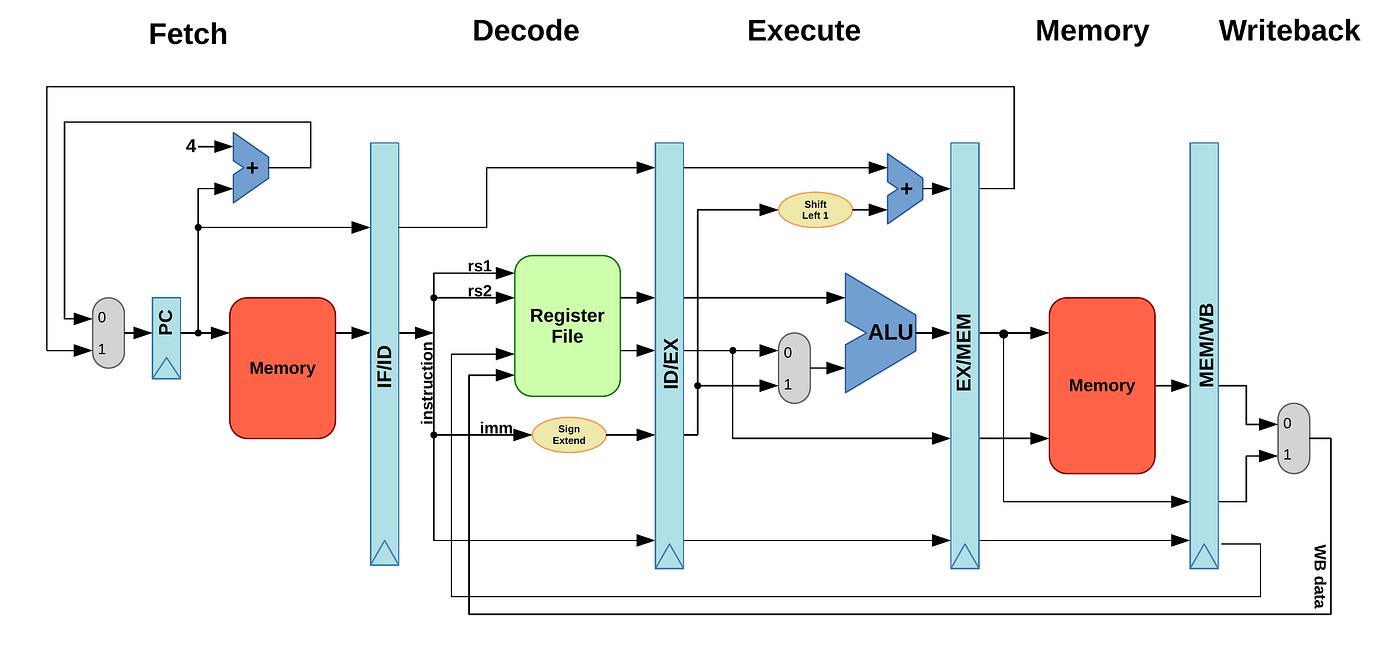
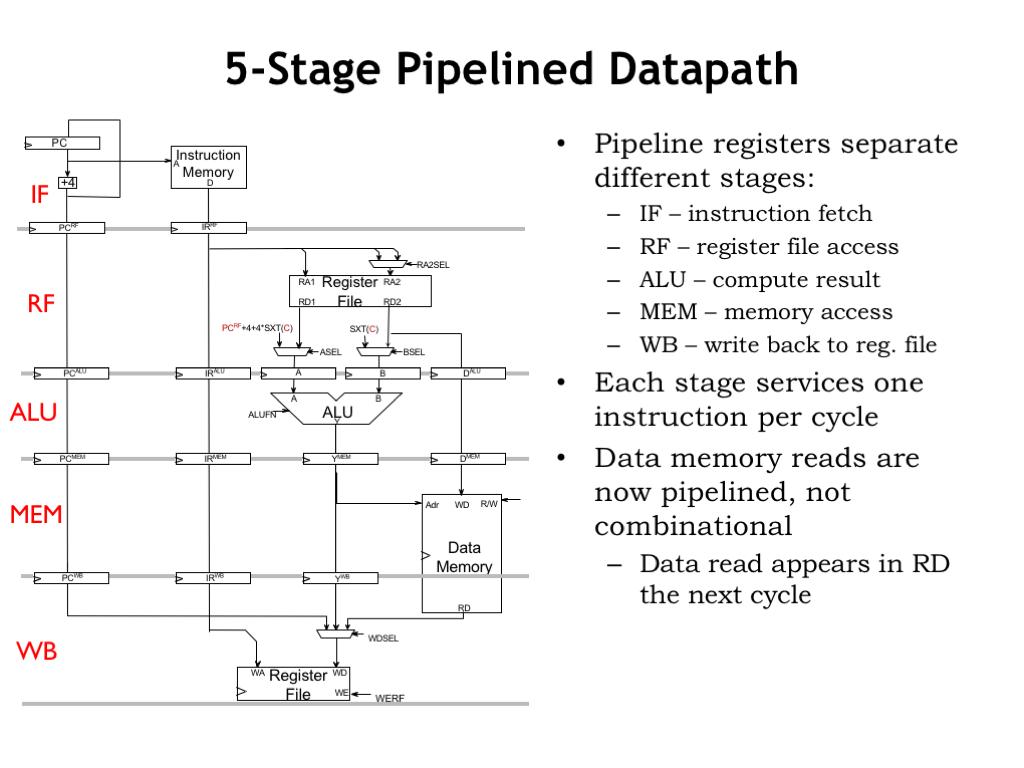
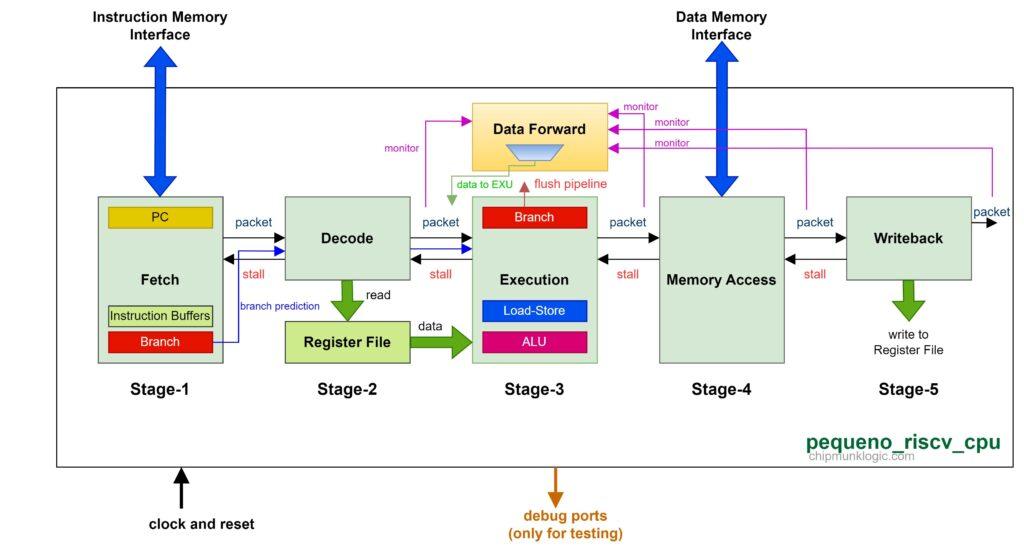
👉 CPU 被拆成5个阶段:
| 阶段 | 作用 |
|---|---|
| IF | 取指令 |
| ID | 解码 |
| EX | 计算 |
| MEM | 访存 |
| WB | 写回 |
👉 每个阶段同时工作
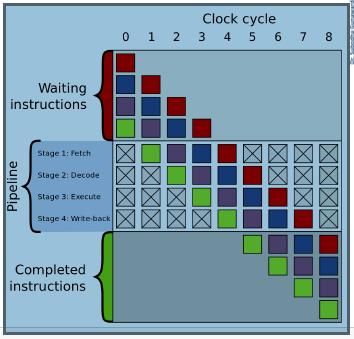
🔄 四、Pipeline 如何运行?
假设3条指令:
|
1 2 |
I1, I2, I3 |
执行过程:
|
1 2 3 4 5 6 |
Cycle 1: I1 (IF) Cycle 2: I1 (ID), I2 (IF) Cycle 3: I1 (EX), I2 (ID), I3 (IF) Cycle 4: I1 (MEM), I2 (EX), I3 (ID) Cycle 5: I1 (WB), I2 (MEM), I3 (EX) |
👉 关键点:
👉 每个周期都有工作在进行
📈 五、性能提升有多大?
单周期:
|
1 2 |
执行3条 = 15个阶段时间 |
Pipeline:
|
1 2 |
执行3条 ≈ 7个周期 |
👉 理想情况:
性能提升接近阶段数(≈5倍)
👉 在实际 CPU 中:
👉 可接近 5–10倍
🚨 六、真正的问题:Hazards(冲突)
Pipeline 的代价:
👉 会出现冲突(Hazards)
🔴 1. Data Hazard(数据依赖)
|
1 2 3 |
ADD x1, x2, x3 ADD x4, x1, x5 |
👉 第二条需要第一条结果
👉 但结果还没写回
👉 问题:数据还没准备好
🔴 2. Control Hazard(分支)
|
1 2 |
BEQ x1, x2, label |
👉 不知道下一条在哪
👉 Pipeline 可能走错路
🔴 3. Structural Hazard(资源冲突)
👉 多个阶段争用同一资源
🛠️ 七、解决方案(核心工程)
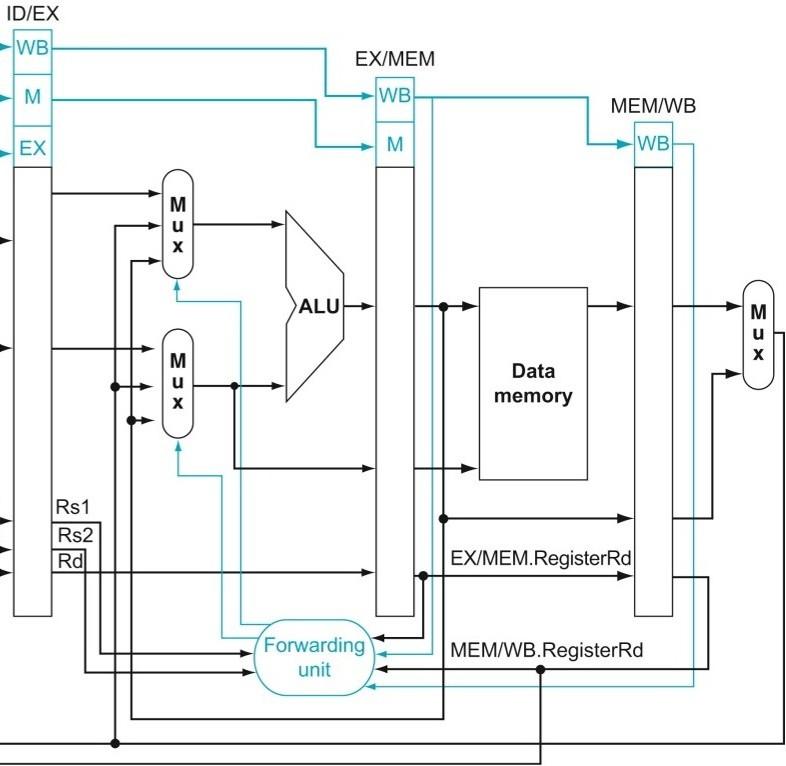
1️⃣ Forwarding(旁路)
👉 直接从 ALU 输出拿数据
👉 不等写回
2️⃣ Stall(暂停)
👉 插入空周期(bubble)
3️⃣ Branch Prediction(预测)
👉 提前猜分支方向
🧠 八、最重要的认知
👉 CPU 的性能不是来自:
❌ 更快的计算
👉 而是:
|
1 2 |
并行执行 + 数据流优化 |
👉 Pipeline 本质:
时间上的并行
⚡ 九、你现在在哪一步?
你已经:
- 做了 Datapath
- 做了单周期 CPU
👉 现在:
👉 进入真正工程核心
👉 Pipeline 是:
👉 从“能跑”到“能用”的分界线
🚀 十、下一步
👉 《Hazard 解决:Forwarding 和 Stall 实现》
你将:
- 解决数据依赖
- 优化性能
- 让 CPU 更接近真实处理器
📌 总结
- Pipeline = 多条指令并行执行
- 大幅提升吞吐量
- 带来 Hazard 问题
- 需要额外控制逻辑
👉 一句话:
CPU 快,不是因为它算得快,而是因为它不等待.
除教程外,本网站大部分文章来自互联网,如果有内容冒犯到你,请联系我们删除!